Globális jelenségek

Igazából semmilyenhez átlaghoz nem érdemes hasonlítani, de attól is függ, mit akarunk megmutatni (ahogy VáraljaMet mondta, jelen esetben pl. mindegy lenne). De sokkal "informatívabb" (és néha célravezetõbb) lehet pl. egy idõsorban az adatokat a teljes idõsornak a részletes statisztikájához hasonlítani. Csak pár példát mondok, hogy mire lennék kíváncsi:
A (sok éves) globális átlaghoz ugye össze kell gyûjteni az összes (sok éves) földi mérést. A klimatológia azt feltételezi, hogy a T normális eloszlást követ (ez nagyon jó közelítéssel igaz is), ennek van két paramétere, ami véletlenül pont a várható érték (m) és a szórás (s), és ezeket véletlenül pont a számtani közép és a statisztikai szórás képleteivel kell kiszámolni, méghozzá az összes összegyûjtött adatból. (Ez tényleg teljesen véletlen, más eloszlásoknál máshogyan kell, az alap módszer a maximum likelihood, ill. a minimum-khí-négyzet, abból kijön.)
Ha megvan az átlag és a szórás, akkor hajtsunk végre egy transzformációt, legyen Z=(T-m)/s, és ennek az idõsorát vizsgáljuk. Ez a Z standard normál eloszlást követ, aminek nincsen paramétere, ellenben egy rakás konstans, meg egy csomó paraméter nélküli függvény származtatható belõle, ami sok mindenre használható. Pl. az integrálja -1-tõl 1-ig 0,68, -2-tõl 2-ig 0,95, -3-tól 3-ig 0,997, ami szemléletesen azt jelenti, hogy egy adatsorban az adatsor átlagának +-1 szórásán belül 68% eséllyel fordul elõ, +-2 szórásán belül 95%-kal, stb.
Ennek tudatában nézzük meg, hogy milyen Z értékeket kaptunk. Legfontosabb a kapott legkisebb és legnagyobb Z érték. (Ha pl. az jön ki, hogy az évi átlagok Z-je -0,1 és +0,1 között mozog, akkor jó stabil a klíma.) Vagy nézzük meg adottnál (pl. -1, -2-nél) kisebb és (+1, +2-nél) nagyobb értékek elõfordulási gyakoriságát, illetve e gyakoriságnak az idõbeli változását (szaporodnak-e vagy fogynak, stb). Esetleg olyat is lehetne nézni, hogy megjelenik-e ferdeség vagy csúcsosság az adatokban. Ez mondjuk azért nehéz ügy, mert maga a feltételezett eloszlás esetén ez mindkettõ pontosan nulla, és nincs több paraméter ezeket kezelni, így ezt csak statisztikai alapon lehetne vizsgálni, valószínûségi alapon nem nagyon.
Ki lehet számolni az évekre a statisztikákat (mk és sk a k-adik évre), és ebbõl meg lehet mondani, hogy milyen lesz az eloszlása az adott év Zk-jának. Ez a Zk nem lesz standard normális, hanem Mk=(mk-m)/s és Sk=sk/s értékekkel lesz normális. Ebbõl kiderül, hogy hány % valószínûséggel lehetett melegebb az adott év egy adott mérõhelyen az átlagnál, hánnyal hidegebb, mekkora eséllyel lehetett adottnál (vagy a szokásosnál) szélsõségesebb, stb.
Vagy meg lehetne csinálni a következõt:
Legyen az egyes évek statisztikája m(t=tk) és s(t=tk) paraméterû normál eloszlású. Legyen az eloszlás maga idõfüggõ, ró(T,m(t),s(t)). A két paraméter idõfüggését feltételezhetjük, hogy valamilyen függvény szerint változnak (ezt hívjuk klímaváltozásnak, aki esetleg még nem hallott róla ). Ezeknek a függvényeknek vannak paramétereik. Ezeket a paramétereket kaphatjuk meg illesztéssel (de vigyázzunk, itt az illesztett és a mért ró értékeket kell összehasonlítani, nem pedig az m és s értékeket, az illesztés tehát a ró függvényre vonatkozik, ez pedig elbonyolítja az eljárást). Megnézhetjük maga a hõmérséklet éves, az évi átlag és szórás idõszakos változásának nagyságrendjét a teljes szóráshoz viszonyítva, és kiderülhet, hogy mennyire szignifikánsak a változások.
). Ezeknek a függvényeknek vannak paramétereik. Ezeket a paramétereket kaphatjuk meg illesztéssel (de vigyázzunk, itt az illesztett és a mért ró értékeket kell összehasonlítani, nem pedig az m és s értékeket, az illesztés tehát a ró függvényre vonatkozik, ez pedig elbonyolítja az eljárást). Megnézhetjük maga a hõmérséklet éves, az évi átlag és szórás idõszakos változásának nagyságrendjét a teljes szóráshoz viszonyítva, és kiderülhet, hogy mennyire szignifikánsak a változások.
Ezek bonyolult számításokat igénylõ, és valószínûleg terjedelmes vizsgálatok lennének, azonban valószínûleg sokkal többre lennének használhatók az így kapott eredmények.
Csak az a baj, hogy - ahogy e hsz. hosszából is kitûnhet - ezekkel a vizsgálatokkal sokat kellene dolgozni, és benne van a pakliban, hogy bizonyos körök számára nem jó eredményt kapunk. Így egyszerûbb a látványos dolgokkal riogatni.
A (sok éves) globális átlaghoz ugye össze kell gyûjteni az összes (sok éves) földi mérést. A klimatológia azt feltételezi, hogy a T normális eloszlást követ (ez nagyon jó közelítéssel igaz is), ennek van két paramétere, ami véletlenül pont a várható érték (m) és a szórás (s), és ezeket véletlenül pont a számtani közép és a statisztikai szórás képleteivel kell kiszámolni, méghozzá az összes összegyûjtött adatból. (Ez tényleg teljesen véletlen, más eloszlásoknál máshogyan kell, az alap módszer a maximum likelihood, ill. a minimum-khí-négyzet, abból kijön.)
Ha megvan az átlag és a szórás, akkor hajtsunk végre egy transzformációt, legyen Z=(T-m)/s, és ennek az idõsorát vizsgáljuk. Ez a Z standard normál eloszlást követ, aminek nincsen paramétere, ellenben egy rakás konstans, meg egy csomó paraméter nélküli függvény származtatható belõle, ami sok mindenre használható. Pl. az integrálja -1-tõl 1-ig 0,68, -2-tõl 2-ig 0,95, -3-tól 3-ig 0,997, ami szemléletesen azt jelenti, hogy egy adatsorban az adatsor átlagának +-1 szórásán belül 68% eséllyel fordul elõ, +-2 szórásán belül 95%-kal, stb.
Ennek tudatában nézzük meg, hogy milyen Z értékeket kaptunk. Legfontosabb a kapott legkisebb és legnagyobb Z érték. (Ha pl. az jön ki, hogy az évi átlagok Z-je -0,1 és +0,1 között mozog, akkor jó stabil a klíma.) Vagy nézzük meg adottnál (pl. -1, -2-nél) kisebb és (+1, +2-nél) nagyobb értékek elõfordulási gyakoriságát, illetve e gyakoriságnak az idõbeli változását (szaporodnak-e vagy fogynak, stb). Esetleg olyat is lehetne nézni, hogy megjelenik-e ferdeség vagy csúcsosság az adatokban. Ez mondjuk azért nehéz ügy, mert maga a feltételezett eloszlás esetén ez mindkettõ pontosan nulla, és nincs több paraméter ezeket kezelni, így ezt csak statisztikai alapon lehetne vizsgálni, valószínûségi alapon nem nagyon.
Ki lehet számolni az évekre a statisztikákat (mk és sk a k-adik évre), és ebbõl meg lehet mondani, hogy milyen lesz az eloszlása az adott év Zk-jának. Ez a Zk nem lesz standard normális, hanem Mk=(mk-m)/s és Sk=sk/s értékekkel lesz normális. Ebbõl kiderül, hogy hány % valószínûséggel lehetett melegebb az adott év egy adott mérõhelyen az átlagnál, hánnyal hidegebb, mekkora eséllyel lehetett adottnál (vagy a szokásosnál) szélsõségesebb, stb.
Vagy meg lehetne csinálni a következõt:
Legyen az egyes évek statisztikája m(t=tk) és s(t=tk) paraméterû normál eloszlású. Legyen az eloszlás maga idõfüggõ, ró(T,m(t),s(t)). A két paraméter idõfüggését feltételezhetjük, hogy valamilyen függvény szerint változnak (ezt hívjuk klímaváltozásnak, aki esetleg még nem hallott róla
). Ezeknek a függvényeknek vannak paramétereik. Ezeket a paramétereket kaphatjuk meg illesztéssel (de vigyázzunk, itt az illesztett és a mért ró értékeket kell összehasonlítani, nem pedig az m és s értékeket, az illesztés tehát a ró függvényre vonatkozik, ez pedig elbonyolítja az eljárást). Megnézhetjük maga a hõmérséklet éves, az évi átlag és szórás idõszakos változásának nagyságrendjét a teljes szóráshoz viszonyítva, és kiderülhet, hogy mennyire szignifikánsak a változások.Ezek bonyolult számításokat igénylõ, és valószínûleg terjedelmes vizsgálatok lennének, azonban valószínûleg sokkal többre lennének használhatók az így kapott eredmények.
Csak az a baj, hogy - ahogy e hsz. hosszából is kitûnhet - ezekkel a vizsgálatokkal sokat kellene dolgozni, és benne van a pakliban, hogy bizonyos körök számára nem jó eredményt kapunk. Így egyszerûbb a látványos dolgokkal riogatni.
Havazás előrejelzés

Utolsó észlelés
Térképek
Radar
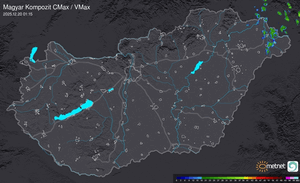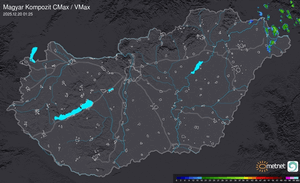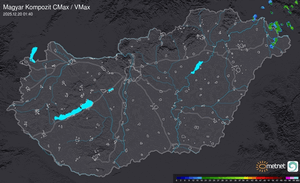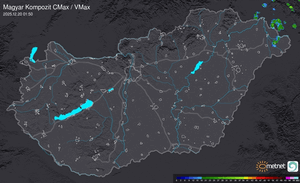
Aktuális hõmérséklet
Aktuális szél
Utolsó kép

2026. Március 23. - Meteorológiai Világnap
MetNet | 2026-03-22 17:25
Szabályzat